Аналіз літературних джерел

Індексування ключовими словами та дескрипторами забезпечує адекватне та точне відображення всього змісту документу, тоді як предметне індексування покликане відображати лише його предметний зміст. Провідні архівні установи світу успішно застосовують індексування та пошук мовою ключових слів. Як приклад, можна виділити Бібліотеку Конгресу, яка має предметний покажчик ключових слів, Бібліотека… Читати ще >
Аналіз літературних джерел (реферат, курсова, диплом, контрольна)
Для розкриття змісту документів в мовах дескрипторного типу каталогізатори на сьогодні найчастіше використовують мову ключових слів, що використовується при змістовній обробці документів [1−3]. Для лексичних одиниць тезауруса характерні співвідношення ієрархічного, синонімічного (еквівалентного) та асоціативного характеру [4]. Деякі дослідники вважають, що асоціативний зв’язок існує між терміном, який визначає предмет, і терміном, який вказує на сферу його застосування (наприклад, токарна обробка — машинобудування) та між термінами, які визначають суміжні поняття (наприклад, біржовий індекс — економіка) [5]. Словник ключових слів на відміну від інших інформаційно-пошукових мов (ІПМ) є ненормованим. Таким чином, маємо значні масиви бібліографічної інформації, але неможливо гарантувати якісний повноцінний пошук в рамках системи прогнозування [6].
Формулювання базових принципів пост координатного індексування
Розглянемо координатне (посткоординатне) індексування як один із методів згортання та пошуку інформації. Координатне індексування [coordinate indexing] - інформаційно-пошукова мова вербального (словесного) типу, яка передбачає вираження змісту документа множиною ключових слів і/або дескрипторів. При такому підході задаються координати документа у nмірному смисловому полі. В даному методі пошуковий образ документу (ПОД) знаходиться на перетині дескрипторів та ключових слів [7−9]. Сучасний індексатор індексує текст не за словами, а за основними поняттями [9, 10].
До загальновідомої фрази «Міжгалузевий баланс» додамо «галузі в економічній діяльності». Ключове слово [keyword] - лексична одиниця, яка вибирається або формується безпосередньо із опрацьованого першоджерела чи словника ключових слів, несе смислове навантаження, має достатню інформаційну вагу, приведена до стандартної лексикографічної форми, що забезпечує уніфікованість її розуміння та застосування. Ключовими словами в системі прогнозування можуть бути слова, словосполучення, персоналії, абревіатури, хронологічні дані, географічні назви тощо.
Виходячи з практичних міркувань, в рамках отримання релевантних даних для системи прогнозування індексаторам рекомендують брати не більше трьох словоформ для створення одного ключового слова [10]. Середня глибина індексування становить п’ять-десять ключових слів на документ, деякі бібліотеки формують до тридцяти ключових слів [8, 11]. Індексування координатного типу багатогалузевого документа формує один пошуковий образ, використовуючи багатоаспектне індексування. Потенційний відвідувач електронного каталогу архівної установи у вигляді експертної системи повинен бути готовий використовувати ключові слова при формуванні пошукового образу запиту.
Індексування ключовими словами та дескрипторами забезпечує адекватне та точне відображення всього змісту документу, тоді як предметне індексування покликане відображати лише його предметний зміст. Провідні архівні установи світу успішно застосовують індексування та пошук мовою ключових слів [3, 11, 12]. Як приклад, можна виділити Бібліотеку Конгресу, яка має предметний покажчик ключових слів, Бібліотека Університету Торонто, Університету Західної Австралії, Бібліотека Каліфорнійського університету, Бібліотека Швеції, Національна бібліотека Франції та ін. Показовим прикладом є Бібліотека Конгресу при Quick search — де застосовується швидкий пошук і основний пошук — Basic search (за бібліографічними параметрами), інтерактивному й керованому покроковому пошуку — Guided search, пропонує використовувати ключові слова, які приводять користувача до бібліографічного опису документа з розгорнутою предметною рубрикою, де він і робить остаточний вибір.
Не застосовуючи в роботі індексування ключовими словами, архіви обмежують доступ користувачів до інформації, звужуючи можливість пошуку релевантного (відповідного інформаційному запиту) та пертиентного (відповідного інформаційній потребі) документа, працюють контрпродуктивно, свідомо позбавляючи споживача значного пласту інформації. У випадку складання часових рядів для побудови моделі прогнозу не можна покладатись лише на автоматичне індексування окремих полів бібліографічного запису та на можливості булевих алгоритмів пошуку. Це стосується усіх видів документальних джерел, але особливу увагу при обробці докуменатційних джерел слід приділити статистичній та науковій літературі.
Виходячи з практики побудови пошукових систем і беручи за основу схему, можна зауважити, що ключові слова не входять у тезаурус, бо потрапивши туди, вони автоматично стають дескрипторами або недескрипторами (нондескрипторами) [13]. Вони існують самостійно чи в нормалізованих, приведених до стандартної форми запису, словниках ключових слів, краще тематичного напряму, де відсутні будь-які зв’язки між словами та в документах, над якими буде працювати індексатор і створювати ключові слова в процесі вільного індексування. Це досить прогресивна та складна діяльність, бо вона дає змогу використовувати ключові слова (КС), які характеризують саме цей документ, а не будь-який інший, застосовуючи термінологію автора, і тоді ПОД набуває індивідуального забарвлення, зазнаючи ідентифікації [14].
Ключові слова надають доступ до інформації електронного каталогу для користувачів. Ключові слова — це оператори пошуку та термінологічний вхід до БД бібліотеки. Від їхньої якості залежить ефективність пошуку в ІПС, тоді як предметна рубрика — предметний вхід у БД.
Головне завдання індексатора — це вибір та формулювання КС [6]. Уведемо основні означення:
предмет — коло знань, об'єкт;
термін — слово або словосполучення, що означає чітко окреслене поняття якої-небудь галузі, науки, техніки, мистецтва, суспільного життя тощо;
поняття — сукупність поглядів на що-небудь.
Координатне індексування відбувається також при використанні дескрипторів [descriptor] - лексичної одиниці вербальної ІПМ, яка вибирається не з тексту, а зі спеціального словника, а також лексична одиниця, що є іменем класу синонімічних або близьких за смислом ключових слів. Дескриптори відрізняються від ключових слів притаманною їм смисловою однозначністю, вони входять до інформаційнопошукового словника — тезауруса [10].
В рамках інформаційної технології прогнозування інформаційно-пошуковий тезаурус — словник, який вміщує дескриптори, дозволені для використання при індексуванні лексичні одиниці, які пов’язані між собою парадигматичними відношеннями, та недескриптори. Зрозуміло, що дескриптори не можуть мати між собою еквівалентних, синонімічних зв’язків. Тезаурус відрізняється від словника ключових слів однозначністю термінів та наявністю парадигматичних зв’язків. Для технології прогнозування існує сенс запропонувати таку методику створення тезауруса:
- — накопичення словника ключових слів;
- — формулювання ключових слів та їхня нормалізація (число, відмінок тощо);
- — дескрипторизація ключових слів (відбувається групування ключових слів у класи, з еквівалентних ключових слів вибирається одне, яке вважається представником певного класу і призначається «дескриптором»);
- — ліквідування омонімії та полісемії шляхом застосування реляторів, символів чи слів, які вказують на різні значення терміна (релятори зазначаються у дужках);
- — встановлення парадигматичних співвідношень (рід — вид, ціле — частина, асоціативних зв’язків).
Під асоціативними співвідношеннями розуміють усі види відношень, крім ієрархічних. Американський стандарт визначає асоціативний зв’язок як такий, коли один термін обумовлює використання іншого (наприклад, народжуваність — соціологія).
Ефективнішими в рамках системи прогнозування можна вважати тезауруси тематично векторні, але такі тезауруси передбачають застосування векторних пошукових алгоритмів.
Створення галузевих тезаурусів чи вбудованих тематичних мікротезаурусів у так звані універсальні тезауруси сприятиме наповненню наукових термінологічних баз. Галузеве дескрипторне дерево претендує на вичерпність та зручність у використанні як для індексаторів, так і для споживачів інформації. Застосування ключових слів чи дескрипторів або і ключових слів і дескрипторів, тобто координатного індексування, здатне забезпечити досить повне та точне відображення опрацьованої інформації [6]. Існує ймовірність знаходження нерелевантного ресурсу, кількість знайдених нерелевантних документів до загальної кількості документів, так зване випадання.
Показовими прикладами інформаційно-пошукових тезаурусів можуть бути MeSH — універсальний медичний тезаурус для індексування документів медичного спрямування та Eurovoc — Тезаурус Євросоюзу. Детальніше зупинимось на іншому. Багатомовний політематичний інформаційно-пошуковий тезаурус Eurovoc визнаний як міжнародний термінологічний стандарт. Він реалізований відповідно до стандартів ISO 1588−1986 «Guidelines for the establishment and development of monolingual thesauri» («Керівництво з введення і розроблення одномовних тезаурусів») та ISO 5921−1985 «Guidelines for the establishment and development of multilingual thesauri» («Керівництво з введення і розробки багатомовних тезаурусів»), він використовується для індексування та пошуку даних в ІПС документів ЄС. Тезаурус, який охоплює різноманітні напрями діяльності європейських інституцій: політику, міжнародні відносини, законодавство, економіку, культуру, соціальні питання, освіту, комунікації, науку тощо, застосовують у своїй роботі Європарламент, Бюро офіційних публікацій ЄС, парламентські бібліотеки, інформаційно-аналітичні агенції багатьох європейських країн.
Успішний досвід використання тезаурусу Eurovoc, який запроваджений 22 офіційними мовами Європейського Союзу дозволяє сформулювати аналогічну модель для інформаційної технології прогнозування циклів розвитку інтегрованих систем.
Так, усі дескриптори мають рівні права — кожен дескриптор в одній мові обов’язково має відповідний дескриптор в іншій мові [14]. Однак між недескрипторами у різних мовах не визначено еквівалентності. Тезаурус має три форми представлення: абетково-пермутаційну, тематичну, багатомовну. Eurovoc пропонує дворівневу структуру. Верхній рівень визначають теми, які мають двосимвольні коди, наприклад, 16 — «Economics», «Економіка». Нижній рівень виступає як сукупність мікротезаурусів, позначених чотирма цифрами, перші дві з яких показують тему, до якої належить цей мікротезаурус: 1606 — «economic policy» («економічна політика»). Нумерація тем і мікротезаурусів збігається для всіх мов. На екрані Eurovoc представлені дві панелі, які пов’язують вибраний рівень ієрархії: логотип Eurovoc та список тем і мікротезаурусів, список мікротезаурусів і зміст вибраного мікротезауруса або мікротезаурус та його окремий дескриптор. Пошук у тезаурусі здійснюється за допомогою гіперпосилань. Дескриптор можна вибрати, набравши першу літеру його назви.
Індексування документів ЄС ключовими словами здійснюється індексаторами, таке індексування називається ручним або інтелектуальним, та проводяться експерименти з використання автоматизованого концептуального індексування, на що існує до 40 тисяч правил [9]. Індексатори Європарламенту приписують документу три-десять ключових слів. Моніторинг показав, що з сорока слів, отриманих у результаті автоматизованого індексування, три — неправильні, неадекватні.
Поява україномовної версії тезауруса могла б стати значним кроком вперед для розвитку координатного індексування в публічних інформаційних ресурсах країни та платформою для створення національного багатомовного інформаційно-пошукового тезауруса з вбудованими тематичними мікротезаурусами. Розробка тематичних мікротезаурусів за умов оптимальної побудови реляцій забезпечить швидкий захват даних та їх обробку в інформаційній моделі.
Структура предметної рубрики: заголовок, підзаголовки — тематичного, географічного, хронологічного, формального характеру — заважка, дуже складна конструкція для формування ПОД, як і сама мова предметних рубрик залишається більше внутрішньобібліотечною, поки що не уніфікованою, і не є поширеною мовою користувачів електронного середовища.
Архівні установи, що містять багато цінних джерел для формування статистичного часового ряду не завжди можуть запропонувати користувачу ранжування, керування, багатомовність одного й того самого джерела, фолксономію, оперативне обробляння документів, простоту пошуку (в основному використання ключових слів у вигляді токенів), великі масиви оцифрованої інформації, інтерактив, наочність.
Інформація, зібрана з електронних джерел в Internet має й інші характеристики: повтори, інформаційний шум, випадіння, механічність індексування, недостовірність, комерційні вирати, неточність, невідповідність тексту перекладу тощо.
Впровадження гіперпосилань в схему формування тезауруса (рис. 1) робить ЕК електронного архіву мобільною, гнучкою інформаційно-пошуковою системою, придатною для формування з електронної БЗ часового ряду для прогнозування циклів розвитку інтегрованих систем.
Система комплексного індексування документів за умов існування архіву підприємства чи її організації в електронному чи паперовому виді дає можливість проводити полііндексування документів.
Спираючись на наведене вище, можна стверджувати, що координатне індексування можна вважати базовим засобом індексування та пошуку документів в електронному середовищі в рамках інформаційних технологій документообігу для прогнозування циклів розвитку інтегрованих систем (рис. 1).
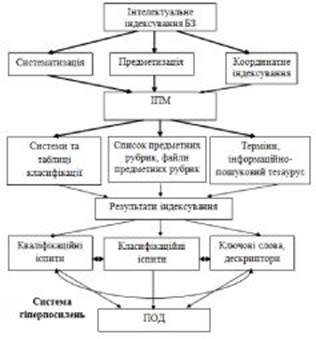
Рис. 1 Система комплексного індексування документів в інформаційній системі
Таким чином, наведена на рис. 1 система комплексного індексування документів в інформаційній системі має прозору схему, побудовану на базі відомих алгоритмів та компонент та може бути організована на основі систем керування банків та баз даних та інтегрована та пошукової системи різної топології та рівня складності.
Результати досліджень На основі виявлених характеристик інформації, таких, як індексатори Європарламенту, Бібліотеки Конгресу, яка має предметний покажчик ключових слів, Бібліотеки Університету Торонто, Університету Західної Австралії, Бібліотеки Каліфорнійського університету, Бібліотеки Швеції, Національної бібліотеки Франції та ін. та існуючих практик пошукових систем, зібраних з електронних джерел, виявлені основні недоліків в практичних методах реалізації обробки інформації, в тому числі в архівних установах. Це дає змогу зформулювати систему комплексного індексування документів в інформаційній системі та метод індексування інформації для побудови процесора обробки даних у системі прогнозування.