Класифікація паралельних обчислювальних систем

Як обчислювальні вузли кластера застосовуються 64 — бітові процесори сім'ї х86 з, мінімум, 512 Мб оперативної пам’яті та 4 Гб вільного дискового простору. На обчислювальних вузлах кластера слід встановити ОС Microsoft Windows Server 2003 (Standard, Enterprise або Compute Cluster Edition). До складу CCP входить Microsoft MPI — версія реалізації стандарту MPI 2 від Argonne National Labs. MS MPI… Читати ще >
Класифікація паралельних обчислювальних систем (реферат, курсова, диплом, контрольна)
Найпоширенішим способом класифікації ЕОМ є систематика Флінна (Flynn), в якій при аналізуванні архітектури обчислювальних систем приділяється увага способам взаємодії способам взаємодії послідовностей (потоків) виконуваних команд та оброблюваних даних В рамках цього підходу розглядаються такі основні типи систем:
- — SISD (Single Instruction, Single Data) — системи, в яких існує одиночний потік команд та одиночний потік даних. До такого типу можна віднести звичайні послідовності ЕОМ;
- — SIMD (Single Instruction, Multiple Data) — системи з одиночним потоком команд та множинним потоком даних. Подібний клас складають багатопроцесорні обчислювальні системи, в яких в кожний момент часу може виконуватися одна і та ж команда для обробки декількох інформаційних елементів; таку архітектуру мають зокрема багатопроцесорні системи з єдиним пристроєм управління. Цей підхід використовувався в попередні роки (системи ILLIAC IV чи СМ-1 компанії Thinking Machines), останнім часом його застосування обмежено, в основному, створенням спеціалізованих систем;
- — MISD (Multiple Instruction, Single Data) — системи, в яких існує множинний потік команд та одиночний потік даних. Стосовно цього типу систем немає єдиної думки: ряд спеціалістів вважають, що прикладів конкретних ЕОМ, які відповідають цьому типу обчислювальних систем, не існує і введення такого класу застосовується для повноти класифікації; інші спеціалісти відносять до даного типу, наприклад, систолічні обчислювальні системи чи системи з конвеєрною обробкою даних;
- — MIMD (Multiple Instruction, Multiple Data) — системи з множинним потоком команд та множинним потоком даних. До подібного класу відноситься більшість паралельних багатопроцесорних обчислювальних систем.
Систематика Флінна широко використовується при конкретизації типів комп’ютерних систем, але вона призводить до того, що практично всі типи паралельних систем, незважаючи на їх істотну різнорідність, виявляються віднесеними до однієї групи MIMD. В результаті вживаються спроби деталізації систематики Флінна. Для класу MIMD запропонована загальновизнана структурна схема, в якій подальше розділення типів багатопроцесорних систем базується на використовуваних способах організації оперативної пам’яті в цих системах. Такий підхід дає змогу розрізнити два важливих типи багатопроцесорних систем — multiprocessors (мультипроцесори чи системи з спільною пам’яттю, що розділяється) та multicomputers (мультикомп'ютери чи системи з розподіленою пам’яттю).
Мультипроцесори. Для подальшої систематики мультипроцесорів враховується спосіб побудови спільної пам’яті. Перший можливий варіант — використання єдиної, централізованої, спільної пам’яті (shared memory). Такий підхід забезпечує однорідний доступ до пам’яті (uniform memory access чи UMA) і є основою для побудови векторних паралельних процесорів (parallel vector processor чи PVP) та симетричних мультипроцесорів (symmetric multiprocessor чи SMP). Прикладами першої групи є суперкомп’ютер Cray T90, другої - IBM eServer, SunStarFire, HP Superdome, SGI Origin та ін. Однією з основних проблем, що виникають при організації паралельних обчислень на цих системах, є доступ з різних процесорів до спільних даних та забезпечення, у зв’язку з цим, однозначності (когерентності) вмісту різних кешів (cache coherence problem). Це тому, що за наявності спільних даних копії значень одних і тих же змінних можуть виявитися і кешах різних процесорів. Якщо за таких обставин, за наявності копій спільних даних, один з процесорів виконає зміну значення розділеної змінної, то значення копій в кешах інших процесорів виявляться такими, що не відповідають дійсності і їх використання призведе до некоректності обчислень. Забезпечення однозначності кешів реалізується на апаратному рівні - для цього після зміни спільної змінної всі копії цієї змінної в кешах відмічаються як недійсні і подальший доступ до змінної потребує обов’язкового звертання до основної пам’яті. Необхідність забезпечення когерентності призводить до деякого зниження швидкості і ускладнює створення систем з достатньо великою кількістю процесорів.
Наявність спільних даних при паралельних обчисленнях приводить до необхідності синхронізації взаємодії одночасно виконуваних потоків команд. Так якщо зміна спільних даних потребує для свого виконання певної послідовності дій, то необхідно забезпечити взаємне виключення (mutual exclusion), щоб ці зміни в будь-який момент часу міг виконувати тільки один командний потік. Задачі взаємного виключення та синхронізації відносяться до числа класичних проблем, і їх розгляд при розробці паралельних програм є одним з основних питань паралельного програмування. Спільний доступ до даних можна забезпечити також при фізичному розподілі пам’яті(тривалість доступу вже не буде однаковою для всіх елементів пам’яті). Такий підхід іменується неоднорідним доступом до пам’яті (non-uniform memory access чи NUMA). Серед систем з таким типом пам’яті виділяють: а) системи, в яких для надання даних використовується тільки локальна кеш-пам'ять наявних процесорів (cache-only memory architecture чи COMA); прикладами є KSR-1 та DDM; б) системи, в яких забезпечується когерентність локальних кешів різних процесорів (cache-coherent NUMA чи CC-NUMA); серед таких систем: SGI Origin 2000, Sun HPC 10 000, IBM/Sequent NUMA-Q2000; в) системи, в яких забезпечується спільний доступ до локальної пам’яті різних процесорів без підтримки на апаратному рівні когерентності кешу (non-cache coherent NUMA чи NCC-NUMA); наприклад, система Cray T3E.
Використання розподіленої спільної пам’яті (distributed shared memory чи DSM) спрощує проблеми створення мультипроцесорів (відомі приклади систем з кількома тисячами процесорів), проте проблеми ефективного використання розподіленої пам’яті (час доступу до локальної та віддаленої пам’яті може різнитися на декілька порядків) приводить до істотного підвищення складності паралельного програмування.
Мультикомп’ютери
Це багатопроцесорні системи з розподіленою пам’яттю, які вже не забезпечують спільного доступу до всієї наявної в системі пам’яті (no-remote memory access чи NORMA). Незважаючи на всю схожість подібної архітектури з системами з розподіленою спільною пам’яттю, мультикомп’ютери мають принципову відмінність: кожний процесор системи може використовувати тільки свою локальну пам’ять, в той час як для доступу до даних, розташованих на інших процесорах, слід явним чином виконати операції передачі повідомлень (message passing operations). Такий підхід застосовується за умови побудови двох важливих типів багатопроцесорних обчислювальних систем — масивно-паралельних систем (massively parallel processor) та кластерів (clusters). Серед представників першого типу систем — IBM RS/6000 SP2, Intel PARAGON, ASCI Red, трансп’ютерні системи Parsytec та ін.; прикладами кластерів є, наприклад, системи AC3 Velocity та NCSA NT Supercluster. Характеристикою обчислювальних систем кластерного типу є надзвичайно швидкий розвиток мікропроцесорних обчислювальних систем. Під кластером розуміють множину окремих комп’ютерів, об'єднаних в мережу, для яких за допомогою апаратно-програмних засобів забезпечується можливість уніфікованого управління (single system image), надійного функціонування (availability) та ефективного використання (performance). Кластери можуть бути утворені на основі вже наявних у споживачів окремих комп’ютерів або ж сконструйовані з типових комп’ютерних елементів, що не потребує істотних фінансових витрат. Застосування кластерів може певною мірою усунути проблеми, пов’язані з розробкою паралельних алгоритмів та програм, оскільки підвищення обчислювальної потужності окремих процесорів дає змогу будувати кластери з порівняно невеликої кількості (декілька десятків) окремих комп’ютерів (lowly parallel processing). Тобто для паралельного виконання в алгоритмах розв’язку обчислювальних задач достатньо виділити тільки крупні незалежні частини розрахунків (coarse granularity), що в свою чергу, знижує складність побудови паралельних методів обчислень і зменшує потоки даних, що передаються, між комп’ютерами кластера. Разом з тим організація взаємодії обчислювальних вузлів кластера за допомогою передачі повідомлень приводить до значних часових затримок, що накладає додаткові обмеження на тип розроблюваних паралельних алгоритмів та програм. Звертається увага на відмінність поняття кластера від мережі комп’ютерів (network of workstations чи NOW). Для побудови локальної комп’ютерної мережі використовують більш прості мережі передачі даних (порядку 100 Мбіт/сек). Комп’ютери мережі більше розосереджені, тому користувачі можуть застосувати їх для виконання якихось додаткових робіт. Слід зауважити, що існують також інші способи класифікації обчислювальних систем.
Приклади топології мережі передачі даних. Структура ліній комутації між процесорами обчислювальної системи (топологія мережі передачі даних) визначається, як правило, з врахуванням можливостей ефективної технічної реалізації. Важливу роль при виборі структури мережі відіграє також аналіз інтенсивності інформаційних потоків при паралельному вирішенні найпоширеніших обчислювальних задач. До числа типових топологій зазвичай відносять такі схеми комунікації процесорів (рис. 6.1):
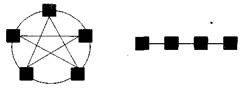
1) Повний граф 2) Лінійка.
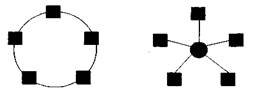
3) Кільце 4) Зірка.
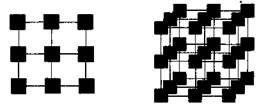
5) 2 — вимірна решітка 6) 3 — вимірна решітка.
Приклади топології багатопроцесорних обчислювальних систем
- — повний граф (completely-connected graph або clique) — система, в якій між будь-якою парою процесорів існує пряма лінія зв’язку. Така топологія забезпечує мінімальні затрати при передачі даних, проте вона має складну реалізацію за умови великої кількості процесорів;
- — лінійка (linear array або farm) — система, в якій всі процесори перенумеровані по порядку і кожний процесор, окрім першого і останнього, має лінії зв’язку тільки з двома сусідніми (з попереднім та наступним) процесорами. Така схема є такою, що реалізується просто, а з іншого боку, відповідає структурі передачі даних при розв’язуванні багатьох обчислювальних задач, наприклад, при організації конвеєрних обчислень;
- — кільце (ring) — ця топологія отримується з лінійки процесорів з'єднанням першого і останнього процесорів лінійки;
- — зірка (star) — система, в якій всі процесори мають лінії зв’язку з певним керуючим процесором. Ця топологія ефективна, наприклад, при організації централізованих схем паралельних обчислень;
- — решітка (mesh) — система, в якій граф ліній зв’язку утворює прямокутну сітку (двовимірну чи тривимірну). Така технологія реалізується достатньо просто, вона може бути ефективно використана при паралельному виконанні багатьох чисельних алгоритмів (наприклад, при реалізації методів аналізу математичних моделей, які описуються диференціальними рівняннями в частинних похідних);
- — гіперкуб (hypercube) — ця топологія є окремим випадком структури решітки, коли за кожною розмірністю сітки є тільки два процесори (тобто гіперкуб містить 2N процесорів при розмірності N). Такий варіант організації мережі передачі даних поширений на практиці і характеризується таким рядом розпізнавальних ознак: два процесори мають з'єднання, якщо двійкові зображення їх номерів мають тільки одну відмінну позицію; в Nвимірному гіперкубі кожний процесор зв’язаний рівно з N сусідами; N — вимірний гіперкуб можна розділити на два (N-1) — вимірних гіперкуби (всього можливі N таких варіантів розбиття); найкоротший шлях між двома будь-якими процесорами має довжини, яка співпадає з кількістю відмінних бітових значень в номерах процесорів (ця величина називається відстанню Хеммінга). обчислювальний програмний комп’ютерний мультипроцесор
Топологія мережі обчислювальних кластерів
Для побудови кластерної системи в багатьох випадках використовують комутатор (switch), через який процесори кластера є повними графами, рис. 6.1, і у відповідності з яким передача даних може бути організована між будь-якими двома процесорами мережі. Одночасність виконання декількох комунікаційних операцій обмежена — в будь-який момент часу кожний процесор може приймати участь лише в одній операції прийому-передачі даних. В результаті паралельно можуть виконуватися тільки ті комунікаційні операції, в яких взаємодіючі пари процесорів не перетинаються між собою.
Характеристики топології мережі
Як основні характеристики топології мережі передачі даних використовуються такі показники:
- — діаметр — показник, який визначається як максимальна відстань між двома процесорами мережі (такою відстанню є величина найкоротшого шляху між процесорами). Ця величина може характеризувати максимально необхідний час для передачі даних між процесорами, оскільки час передачі пропорційний довжині шляху;
- — зв'язність (connectivity) — показник, який характеризує наявність різних маршрутів передачі даних між процесорами мережі. Конкретний вигляд цього показника можна визначити як мінімальна кількість дуг, які слід видалити для розділення мережі передачі даних на дві незв’язні області;
- — ширина бінарного поділу (bisection width) — показник, який визначається як мінімальна кількість дуг, які слід видалити для розділу мережі передачі даних на дві незв’язні області однакового розміру;
- — вартість — показник, який можна визначити, наприклад, як загальна кількість ліній передачі в багатопроцесорній обчислювальній системі.
Для порівняння в таблиці 6.1 наводяться значення перерахованих показників для різних топологій мережі передачі даних.
Таблиця Характеристики топологій мережі передачі даних (р — кількість процесорів).
Топологія. | Діаметр | Ширина бісекції. | Зв’язність. | Вартість. | |
Повний граф. | p2/4. | p-1. | P (p-1)/2. | ||
Зірка. | p-1. | ||||
Повне двійкове дерево. | 2log ((p+1)/2). | p-1. | |||
Лінійка. | p-1. | p-1. | |||
Кільце. | [p/2]. | P. | |||
Решітка N=2. | 2(-1). | 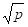 | 2(p-). | ||
Решітка-тор N=2. | 2[/2]. | 2p. | |||
Гіперкуб. | log p. | p/2. | log p. | (p log p)/2. | |
Характеристика системних платформ для побудови кластерів
За системну платформу для побудови кластерів використовують обидві поширені нині операційні системи Unix та Microsoft Windows. Далі розглядатимемо рішення на основі ОС сім'ї Microsoft Windows. Microsoft Compute Cluster Server 2003 (CCS) є інтегрованою платформою для підтримки високопродуктивних обчислень на кластерних системах. CCS складається з операційної системи Microsoft Windows Server 2003 та Microsoft Compute Cluster Pack (CCP) — набору інтерфейсів, утиліт та інфраструктури управління. Разом з ССР постачається SDK, який містить необхідні інструменти розробки програм для CCS, включно власну реалізацію MPI (Microsoft MPI). Окрім того, до Microsoft Compute Cluster Server 2003 логічно примикає Microsoft Visual Studio 2005 — інтегроване середовище розробки (IDE), яке містить компілятор та налагоджування програм, розроблених з використанням технологій MPI та OpenMP.
Як обчислювальні вузли кластера застосовуються 64 — бітові процесори сім'ї х86 з, мінімум, 512 Мб оперативної пам’яті та 4 Гб вільного дискового простору. На обчислювальних вузлах кластера слід встановити ОС Microsoft Windows Server 2003 (Standard, Enterprise або Compute Cluster Edition). До складу CCP входить Microsoft MPI — версія реалізації стандарту MPI 2 від Argonne National Labs. MS MPI сумісна з МРІСН 2 і підтримує повнофункціональний АРІ з більш ніж 160 функціями. MS MPI у Windows Compute Cluster Server 2003 задіє WinSock Direct протокол для найкращої продуктивності та ефективного використання центрального процесора. MS MPI може використати будь-яке Ethernet з'єднання, яке підтримується Windows Server 2003, та з'єднання InfiniBand чи Myrinet, з використанням WinSock Direct драйверів, які постачаються виробниками апаратного забезпечення. MS MPI підтримує мови програмування C, Fortran 77, Fortran 90, a Microsoft Visual Studio 2005 включає паралельне налагоджування, яке працює з MS MPI. Розробники можуть запустити свій MPI — додаток на декількох обчислювальних вузлах, та Visual Studio автоматично з'єднатися з процесами на кожному вузлі, надаючи змогу розробнику призупиняти додаток і проглядати значення змінних в кожному процесі окремо.
Крім реалізації MPI до складу ССР входить зручна система планування завдань, яка дає змогу проглядати стан всіх запущених задач, збирати статистику, призначати запуски програм на певний час, завершувати «завислі» задачі, та ін. В поточній версії робота можлива або через графічний інтерфейс, або через командну стрічку. В остаточній версії буде передбачена можливість звертання до системи та через інші інтерфейси: СОМ, web — сервіс, та ін. Windows Compute Cluster Server 2003 підтримує 5 різних мережевих технологій, причому кожний вузол може мати від 1 до 3 мережевих карток. Правильний вибір використовуваної технології необхідний для оптимального функціонування обчислювального кластера.