Алгоритм Лемпеля — Зіва — Велча

Спочатку створимо початковий словник одиничних символів. У стандартній кодуванні ASCII є 256 різних символів, тому, для того, щоб всі вони були коректно закодовані (якщо нам невідомо, які символи будуть присутні у вихідному файлі, а які — ні), початковий розмір коду буде дорівнює 8 бітам. Якщо нам заздалегідь відомо, що в початковому файлі буде менша кількість різних символів, то цілком розумно… Читати ще >
Алгоритм Лемпеля — Зіва — Велча (реферат, курсова, диплом, контрольна)
Алгоритм Лемпеля — Зива — Велч (Lempel-Ziv-Welch, LZW) — це універсальний алгоритм стиснення даних без втрат, створений Авраамом Лемпелем (англ. Abraham Lempel), Яаковом Зивом (англ. Jacob Ziv) і Террі Велчем (англ. Terry Welch). Він був опублікований Велчем в 1984 році, в якості поліпшеної реалізації алгоритму LZ78, опублікованого Лемпелем і Зивом в 1978 році. Алгоритм розроблений так, щоб його можна було швидко реалізувати, але він не обов’язково оптимальний, оскільки він не проводить ніякого аналізу вхідних даних.
Процес стиснення виглядає наступним чином. Послідовно зчитуються символи вхідного потоку і відбувається перевірка, чи існує в створеній таблиці рядків такий рядок. Якщо такий рядок існує, зчитується наступний символ, а якщо рядок не існує, в потік заноситься код для попередньої знайденої рядки, рядок заноситься в таблицю, а пошук починається знову.
Наприклад, якщо стискають байтові дані (текст), то рядків в таблиці виявиться 256 (від «0» до «255»). Якщо використовується 10-бітний код, то під коди для рядків залишаються значення в діапазоні від 256 до 1023. Нові рядки формують таблицю послідовно, т. Е. Можна вважати індекс рядка її кодом.
Алгоритмом декодування на вході потрібно тільки закодований текст, оскільки він може відтворити відповідну таблицю перетворення безпосередньо по закодованого тексту. Алгоритм генерує однозначно декодіруемий код за рахунок того, що кожен раз, коли генерується новий код, новий рядок додається в таблицю рядків. LZW постійно перевіряє, чи є рядок вже відомої, і, якщо так, виводить існуючий код без генерації нового. Таким чином, кожен рядок буде зберігатися в єдиному екземплярі і мати свій унікальний номер. Отже, при дешифрування при отриманні нового коду генерується новий рядок, а при отриманні вже відомого, рядок івлекается зі словника.
Псевдокод алгоритма.
- 1. Ініціалізація словника усіма можливими односимвольних фразами. Ініціалізація вхідний фрази щ першим символом повідомлення.
- 2. Вважати черговий символ K з кодованого повідомлення.
- 3. Якщо КОНЕЦ_СООБЩЕНІЯ, то видати код для щ, інакше:
- 4. Якщо фраза щ (K) вже є в словнику, привласнити вхідний фразі значення щ (K) і перейти до кроку 2, інакше видати код щ, додати щ (K) в словник, привласнити вхідний фразі значення K і перейти до кроку 2.
- 5. Кінець.
Приклад Просто по псевдокоду зрозуміти роботу алгоритму не дуже легко, тому розглянемо приклад стиснення і декодування зображення.
Спочатку створимо початковий словник одиничних символів. У стандартній кодуванні ASCII є 256 різних символів, тому, для того, щоб всі вони були коректно закодовані (якщо нам невідомо, які символи будуть присутні у вихідному файлі, а які - ні), початковий розмір коду буде дорівнює 8 бітам. Якщо нам заздалегідь відомо, що в початковому файлі буде менша кількість різних символів, то цілком розумно зменшити кількість біт. Щоб форматувати таблицю, ми встановимо відповідність коду 0 відповідному символу з двійкового кодом 0, тоді 1 відповідає символу з кодом 1, і т.д., до коду 255. Насправді ми вказали, що кожен код від 0 до 255 є кореневим.
Більше в таблиці не буде інших кодів, що володіють цією властивістю.
У міру зростання словника, розмір груп повинен зростати, з тим, щоб врахувати нові елементи. 8-бітові групи дають 256 можливих комбінації біт, тому, коли в словнику з’явиться 256-е слово, алгоритм повинен перейти до 9-бітовим групам. При появі 512-ого слова станеться перехід до 10-бітовим групам, що дає можливість запам’ятовувати вже +1024 слова і т.д.
У нашому прикладі алгоритму заздалегідь відомо про те, що буде використовуватися лише 5 різних символів, отже, для їх зберігання буде використовуватися мінімальна кількість біт, що дозволяє нам їх запам’ятати, тобто 3 (8 різних комбінацій).
Кодування Нехай ми стискаємо послідовність «abacabadabacabae».
- § Крок 1: Тоді, відповідно до викладеного вище алгоритму, ми додамо до спочатку порожній рядку «a» і перевіримо, чи є рядок «a» в таблиці. Оскільки ми при ініціалізації занесли в таблицю всі рядки з одного символу, то рядок «a» є в таблиці.
- § Крок 2: Далі ми читаємо наступний символ «b» з вхідного потоку і перевіряємо, чи є рядок «ab» в таблиці. Такий рядки в таблиці поки немає.
- § Додаємо в таблицю «ab». У потік: ;
- § Крок 3: «ba» — немає. У таблицю: «ba». У потік: ;
- § Крок 4: «ac» — немає. У таблицю: «ac». У потік: ;
- § Крок 5: «ca» — немає. У таблицю: «ca». У потік: ;
- § Крок 6: «ab» — є в таблиці; «Aba» — немає. У таблицю: «aba». У потік: ;
- § Крок 7: «ad» — немає. У таблицю: «ad». У потік: ;
- § Крок 8: «da» — немає. У таблицю: «da». У потік: ;
- § Крок 9: «aba» — є в таблиці; «Abac» — немає. У таблицю: «abac». У потік: ;
- § Крок 10: «ca» — є в таблиці; «Cab» — немає. У таблицю: «cab». У потік: ;
- § Крок 11: «ba» — є в таблиці; «Bae» — немає. У таблицю: «bae». У потік: ;
- · Крок 12: І, нарешті останній рядок «e», за нею йде кінець повідомлення, тому ми просто виводимо в потік .
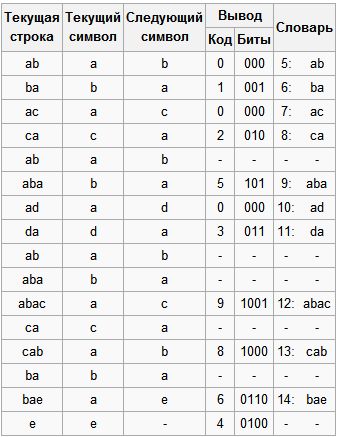
Рисунок 1.1 — Таблиця кодування
Отже, ми отримуємо закодоване повідомлення «0 1 0 2 5 0 3 9 8 6 4», що на 11 біт коротше.
Декодування Особливість LZW полягає в тому, що для декомпресії нам не треба зберігати таблицю рядків в файл для розпакування. Алгоритм побудований таким чином, що ми в змозі відновити таблицю рядків, користуючись тільки потоком кодів.
Тепер уявімо, що ми отримали закодоване повідомлення, наведене вище, і нам потрібно його декодувати. Перш за все, нам потрібно знати початковий словник, а наступні записи словника ми можемо реконструювати вже на ходу, оскільки вони є просто конкатенацией попередніх записів[5].
Рисунок 1.2 — Таблиця декодування